Ok, this post is going a little bit out of my field. If anyone can fill in some of the gaps in my understanding of phylogenetics and in how to get from there to the math, please do so in the comments. So, anyway, phylogenetics is the study of how various organisms are related, and is very closely related to taxonomy, the classification of organisms. It doesn’t look, at first, like it’s the sort of thing that would grab techniques from algebraic geometry, the study of solutions to polynomial equations. My thought is that it just looks too hard on the surface to hope to have anything nice popping out mathematically that’s that elementary. Well…that’s wrong. Without realizing it, algebraic geometers have been looking at problems relevant to phylogenetics for quite some time.
Let  be a tree. That is, take some collection of vertices
be a tree. That is, take some collection of vertices  and a collection of edges
and a collection of edges  connecting pairs of vertices such that there are no loops and the whole thing is connected. In fact, we’ll have a distinguished vertex called the root, which we think of as the starting point for the tree. At the root, we stick a vector
connecting pairs of vertices such that there are no loops and the whole thing is connected. In fact, we’ll have a distinguished vertex called the root, which we think of as the starting point for the tree. At the root, we stick a vector  , which is a probability vector (ie, the entries add to one) and which has
, which is a probability vector (ie, the entries add to one) and which has  entries. We call this the number of states, and we think of as a probability distribution: what is the chance that the root is in state
entries. We call this the number of states, and we think of as a probability distribution: what is the chance that the root is in state  ? By definition, it’s
? By definition, it’s 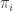 .
.
So now there’s the rest of the tree. Along each edge, we stick a  matrix, whose
matrix, whose  element represents the probability of the system moving from state to state
element represents the probability of the system moving from state to state  . We can put a new matrix on each edge if we like. So now we’ve got a whole mess of variables representing the probability distribution we started with and how the distribution can change. So now, each vertex can be taken to be a random variable with possible states by giving it the distribution multiplied by the matrices of the unique chain of edges from the root to the vertex.
. We can put a new matrix on each edge if we like. So now we’ve got a whole mess of variables representing the probability distribution we started with and how the distribution can change. So now, each vertex can be taken to be a random variable with possible states by giving it the distribution multiplied by the matrices of the unique chain of edges from the root to the vertex.
Now, for any reasonable modeling in phylogenetics, we need to constrain the entries of the matrices and the entries of in biologically sensible ways. So we had a system of  variables, that is, the entries of the matrices and the vector , and we put in some constraints, which gives us a subset
variables, that is, the entries of the matrices and the vector , and we put in some constraints, which gives us a subset  of
of  . So specifying is the same as determining a model for evolution. More on that in a moment.
. So specifying is the same as determining a model for evolution. More on that in a moment.
So now say that there are  leaves, with a leaf just being a vertex in our tree which is only contained in one edge. Then at each leaf, we can see possible outcomes. That is, the leaf can be in any of the states that we’re looking at. So there are
leaves, with a leaf just being a vertex in our tree which is only contained in one edge. Then at each leaf, we can see possible outcomes. That is, the leaf can be in any of the states that we’re looking at. So there are 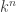 possible outcomes, and given and all the matrices, we can at least write down probabilities for all of them. In fact, and here’s where the algebraic geometry begins, the probability of any given outcome is given as a polynomial in the entries of the matrices and ! So we get a polynomial map
possible outcomes, and given and all the matrices, we can at least write down probabilities for all of them. In fact, and here’s where the algebraic geometry begins, the probability of any given outcome is given as a polynomial in the entries of the matrices and ! So we get a polynomial map 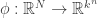 .
.
Now, from this we have complete freedom in all of our variables, so the map only relies on the tree and the number of states. Not terribly good for us. However, we have  which actually defines our model, so what we should be interested in is
which actually defines our model, so what we should be interested in is 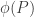 . So what can we say about this image? Well, probability dictates that is contained in the standard
. So what can we say about this image? Well, probability dictates that is contained in the standard 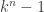 simplex, simply because the image consists of probability vectors, and so the entries must add up to one.
simplex, simply because the image consists of probability vectors, and so the entries must add up to one.
Before doing any more, a very simple example is in order. We’ll look at the binary tree with three leaves. That means that there’s the root, then there’s two edges  and
and  . Then, off of , there are two more edges
. Then, off of , there are two more edges  and
and  , and the vertices at the end of
, and the vertices at the end of 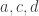 are the three leaves. We’ll also take
are the three leaves. We’ll also take 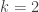 , so that our tree gives a binary random variable.
, so that our tree gives a binary random variable.
Assume the first leaf, attached to , is in state , the second in and the third in state . Then there’s a polynomial  . Each term represents one possibility. The first, for instance, is the probability that we started in state 0, then moved to state on and that along nothing changed, and then along and we came out with the final configuration we wanted. The other terms have similar meanings, so
. Each term represents one possibility. The first, for instance, is the probability that we started in state 0, then moved to state on and that along nothing changed, and then along and we came out with the final configuration we wanted. The other terms have similar meanings, so  , when given numbers, tells us the probability that the final state will be
, when given numbers, tells us the probability that the final state will be 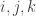 . So we get 8 polynomials which define a map
. So we get 8 polynomials which define a map 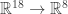 , and in fact give a map on a nine dimensional cube in
, and in fact give a map on a nine dimensional cube in 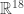 when you remember that all these numbers must be positive, between zero and one, and that pairs of them must add to 1, as they are probailities.
when you remember that all these numbers must be positive, between zero and one, and that pairs of them must add to 1, as they are probailities.
We’re going to ignore that, however, and notice that this gives a set of perfectly good polynomials if we plug in complex numbers. Additionally, we’re not really working on  at this point. Each matrix acts as homogeneous coordinates on a copy of
at this point. Each matrix acts as homogeneous coordinates on a copy of 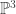 and the starting probability vector acts as coordinates on
and the starting probability vector acts as coordinates on  . In fact, by working over projective space, we are kind of preserving the probability issues, because we can always choose homogeneous coordinates for a point which sum up to one. So our map is really
. In fact, by working over projective space, we are kind of preserving the probability issues, because we can always choose homogeneous coordinates for a point which sum up to one. So our map is really  .In general, we’ll get a
.In general, we’ll get a  for each edge and a
for each edge and a  for the probability vector as the domain.
for the probability vector as the domain.
Now back to the biology a little bit. Generally, we’ll have is either two (because the variable is either “yes” or “no”) or else four (usually A,C,G,T, so we’ve got random DNA), and the remaining question regards how can one thing change to another. One model, the general Markov model, is what we did above. We make no assumptions whatsoever on the entries of the matrices, they can be whatever they want. On the other hand, and this one I actually see the biology in, there’s the stationary base composition model. This one doesn’t require anything of the matrix entries, but rather requires that the matrices all have as an eigenvector, so that the distribution of the states stays the same. Say, there’s always the same fraction of nucleotides of each type.
Now I’m going to do a rather simple example in order to illustrate the classical geometry that comes out of it. Start with a root and then two leaves, so it’s a tree with exactly two edges. Give these edges the same matrix and take . Then we’ll further require that the matrix be of the form ![\left[\begin{array}{cc}a_0&a_1\\a_1&a_0\end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7Da_0%26a_1%5C%5Ca_1%26a_0%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Then we get
. Then we get  , which simplifies out to
, which simplifies out to  ,
,  and
and  . Now, working with Groebner bases to eliminate the
. Now, working with Groebner bases to eliminate the 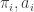 variables, this tells us that the image is
variables, this tells us that the image is  . In fact, we can get a bit more out of this if we try: it turns out to be the map given by the Segre embedding of
. In fact, we can get a bit more out of this if we try: it turns out to be the map given by the Segre embedding of  into , followed by a projection down to
into , followed by a projection down to 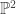 .
.


Wow. The “possibly related posts” connected this blog up to my blog, but it got the wrong post. I’ve spent more than my share of time solving this sort of problem, but in the quantum mechanical equivalent.
For an elementary particle that is made up of several components, that is, a bound state, one finds that this should not depend on time; it must be an eigenstate of the Hamiltonian. Translated into Markov chanis, this means that the probability amplitudes, when written in N-dimensional matrix form, M, should be idempotent, MM = M.
And this gives a set of N coupled quadratic equations in N unkonwns similar to what you’re working on, except for the idempotency. One can take a rather simple set of equations, and from them, get the weak hypercharge and weak isospin quantum numbers of the elementary fermions.
Cool. I really need to get back to studying particle physics…perhaps once my orals are done I’ll have time.
Where’s the graph!? :)
Sadly, I’ve not figured out a good way to put a graph in. Once I do, I will edit…if I remember.
Pingback: Tangled Bank #112 « Science Notes
I draw graphs in MS paint, with a width of 500 pixels, and copy them in using the “image” button of the wordpress editor.
Be sure to click the “high resolution” button, otherwise it munges them.
Pingback: What are some applications outside of mathematics for algebraic geometry? | CL-UAT